or, Why your LLM Revenue Will Be Zero
I’m writing to you from the cradle of Large Language Models (LLMs). Recently we’ve been introduced to GPT, LLaMA, LaMDA, AlexaTM, and others. All of them in just a handful of months. Companies are marketing a surge of generative products built on top of these LLMs: DALL-E, ChatGPT, Bing Chat, Google Bard, Adobe Firefly, and probably a few hundred startups.
I’m here to tell you why most of these products are going to make zero dollars. The argument is simple: LLMs are algorithms, and nobody makes money selling algorithms.
The other me in my brain politely objects: “that certainly doesn’t sound right–What about Google Search?” Hey me, Google Search doesn’t make any money selling an algorithm! They make money running an algorithm on a large dataset.
🤹 That’s right, take off those Twitter swimmies; and right as we breach the max tweet length!1 Where we’re going, we believe in ~N~U~A~N~C~E~.
There’s algorithms, and there’s data. Algorithms are nothing without data. Or was it, data is nothing without algorithms? If some of you Twitter folk are still around, go fight about it! Everyone else, bask with me in nondualism.
Take an algorithm. Quick sort. Who monetizes quick sort? Nobody of course, but also everybody, in a way. Each time you sort a spreadsheet alphabetically, you’re likely running quick sort. And you’re paying someone for your spreadsheet software, (right??? 👮) so they just made money selling an algorithm. Oh woops, we’re doing nuance. You also gave them your data.
Data + Algorithm = 🤑🤑📈
You gave them, specifically them, your data and they ran quick sort on it. But you could have given your data to another spreadsheet software, or a text editing software, or a website with a text box, and they also would have quick sorted it for you. The algorithm is a commodity. You can get it from lots of places and the outcome is always the same, because there’s only one way to alphabetically sort your list. The minimum viable software business then, is more than an algorithm. It’s an algorithm plus access to data.
I had to say ‘access to data’ because in the good old days the data was right next to you, etched onto platters. But now there’s this thing of dubious value we call the internet, and with it you could put your data onto someone else’s platters. Ever ask yourself whose platters your data is etched onto? Like what’s that person’s name? Anyway, your data is over there now. And since you own the data, you get to say who can and can’t access it. And also the people who own the platters get to say who can and can’t access it.
Google Search goes one step further. What if you don’t have to ask anyone for access to their data? What if there was data that wants to be accessed? An entire platter-mountain of consenting data. You could write a matchmaking algorithm that introduces data-wanters to data-havers!
Soo much data. That would be… intoxicating… why, I might become addicted to other people’s data. I might… forget to ask them if they consent to me accessing it. Or no, I might trick them into giving me access. Would I… extort them? I think yes! Tricksy data-havers! Or… no, no, I will not be evil.
That should be enough examples to illustrate the data + algorithm business varietals. Pop your stack, we’re headed back to the LLMs. I’ve already had a deluge of companies reach out to me about their new AI; sounds commodityish, so that must be the algorithmy part. Now then, where’s the data part… Hmm, I can run the AI on my data. But also the AI was trained on some of that definitely-consensual all-data accessible on the internet. I guess LLMs are a way for an algorithm to consume platter-mountains worth of other people’s data, so that it can do clever things with my data. Is that why everyone is so excited? (Yes.)
That sounds like a money maker and it has no problems. Backspace this entire post! Unless, if the algorithm were to accidentally commodify all its training data, then that wouldn’t be very exciting? I’d ask the AI to write my marketing materials, which I want to stand out in a crowd, and it would just make my stuff sound like everyone else’s, which is the opposite of what I want?
Or what if my competitors’ data was in the training data and some of it ends up in my data? Is that a problem? Or could an artist’s data be recreated nearly 1:1 without me even knowing, triggering a copyright violation? Let’s ask an expert on LLMs. Darn, they don’t know. I guess just release the technology and we’ll find out? 😬 There’s no laws against it.
I think that I, a customer of your AI deserve answers! Why do I sound like all of my competitors?! Why do I sound a lot like specifically one of my competitors?! Why did I wake up to 9 copyright violation notices in my mailbox from one… Images Conglomerate LLC?! All my friends got them too?!
Tck-tck-tck-tck 🎢 we’ve reached the top of the coaster. Time for the fall! Let’s ask DALL-E to generate my blog images for me, I hear that’s a business.
DALL-E! Draw me the hype cycle followed by the trough of disillusionment, in the style of a roller coaster!
Fantastic! But just in case you need a little more clarity, here’s the hype cycle graph I found on a boring old search engine:
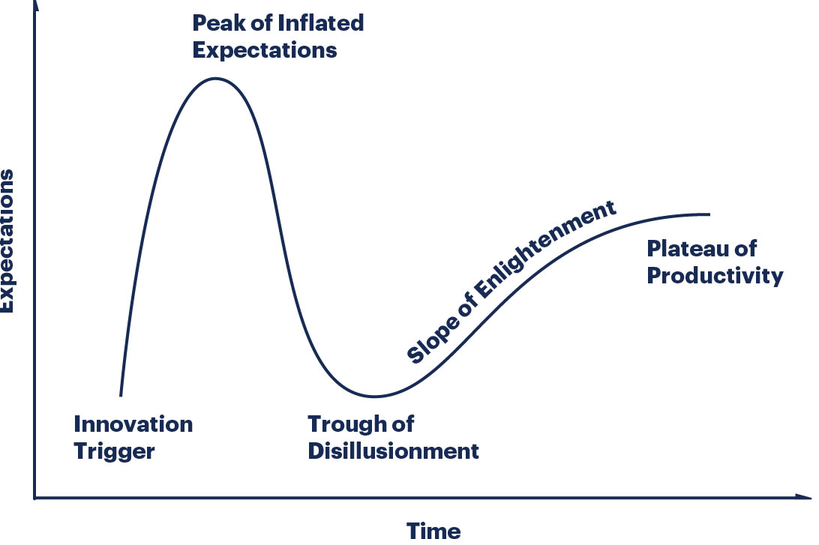
Who emerges from the trough, enlightened? Probably not the people running the algorithm. What about the people who own the training data? They could stand to make some money. What if you sold access to verifiably legal training data, alongside insurance against any legal ramifications when using the training data? Or what if you had a team of in-house artists generating a never-ending stream of novel training data, and all the algorithm did was scale their output? Those might work. Starting to sound like all the money’s in the training data.
Everyone else, you’re about to find out where all the VR helmets went.
-
i didn’t actually count and i don’t even know the max tweet length. social media abstinence flex ↩